"스파크를 다루는 기술 Spark in Action"을 읽고 개인적으로 학습한 내용을 정리하는 포스터 입니다.
자세한 내용은 책을 참조해주세요.
출판사 웹 사이트 : https://www.gilbut.co.kr/book/view?bookcode=BN001997#bookData
1. 스파크란
- 빅데이터 처리를 위한 오픈소스 병렬 분산 처리 플랫폼
- 스파크는 잡에 필요한 데이터를 메모리에 캐시로 저장하는 인-메모리 실행 모델 (맵리듀스의 한계점은 맵리듀스 잡의 결과를 다른 잡에서 사용하려면 결과를 HDFS에 저장해야 함)
- 스칼라, 자바, 파이썬, R 등 다양한 프로그래밍 언어 지원
- 실시간 스트림 데이터 처리, 머신 러닝, SQL 연산, 그래프 알고리즘, 일괄 처리 등 여러 종류의 프로그램을 단일 프레임워크에서 구현 가능
- 스파크는 잡과 태스크를 시작하는 데 시간을 소모하기 때문에 소량의 데이터 처리 시 관계형 데이터베이스나 스크립트가 훨씬 더 빠름
2. 스파크를 구성하는 컴포넌트
스파크 컴포넌트 종류
스파크 코어(Core), 스파크 SQL, 스파크 스트리밍(Streaming), 스파크 GraphX, 스파크 MLlib
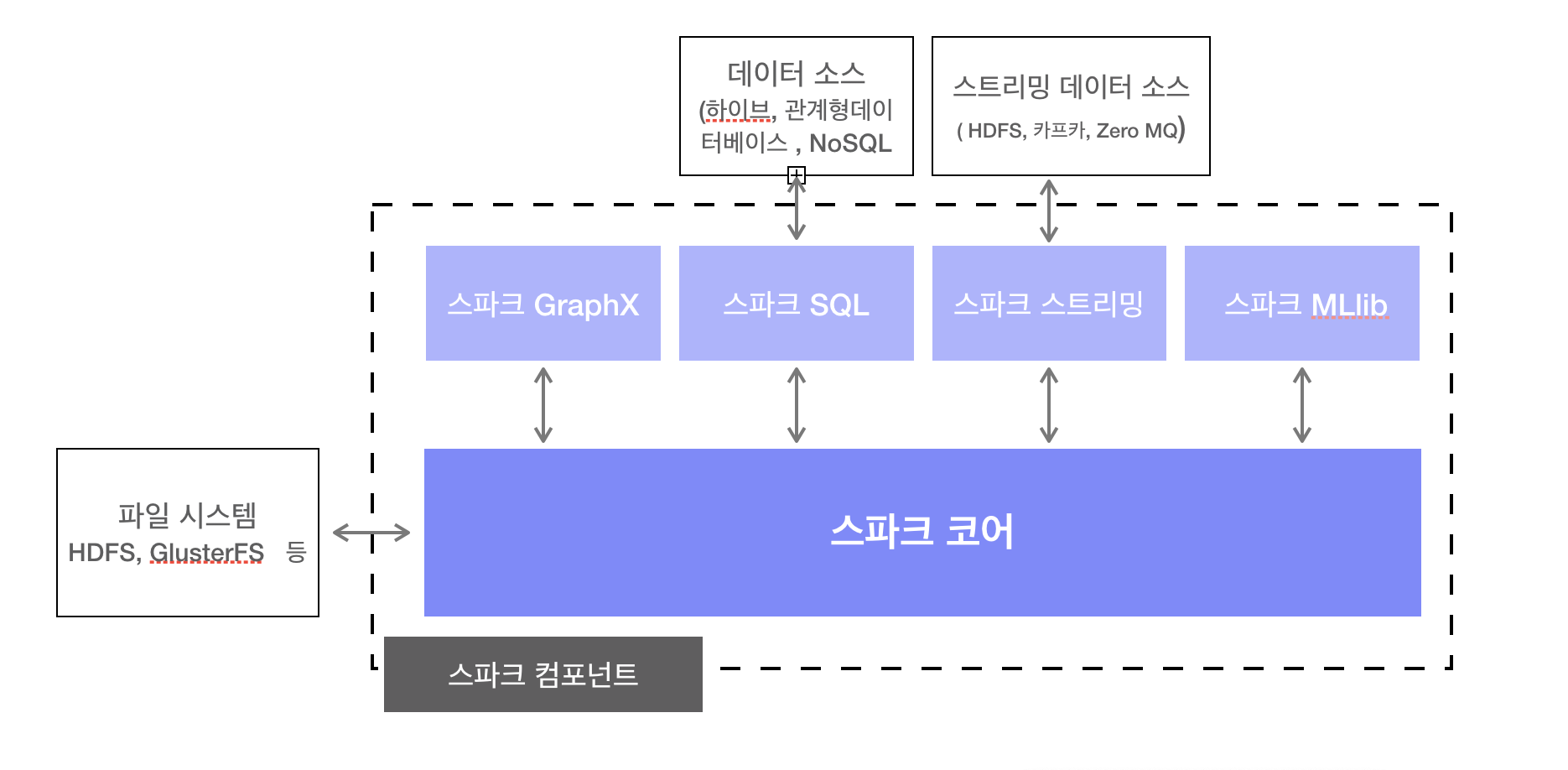
2.1 스파크 코어(Core)
- 스파크 잡과 다른 스파크 컴포넌트에 필요한 기본 기능 제공
- RDD : 분산 데이터 컬렉션(데이터셋)을 추상화한 객체
- 데이터셋에 적용할 수 있는 연산 및 변환 메서드 제공
- 노드 장애 발생 시 데이터셋을 재구성할 수 있는 복원성 갖춤
- 파일 시스템에 접근가능
- HDFS, GlusterFS, 아마존 S3 등...
- 노드간 정보 공유, 네트워킹, 보안, 스케줄링, 데이터 셔플링 기능 구현
2.2 스파크 SQL
- 스파크와 하이브 SQL이 지원하는 SQL을 사용하여 대규모 분산 정형 데이터 다를 수 있는 기능 제공
- DataFrame(spark 1.3), Dataset(Spark 1.6) 에 적용된 연산을 일정 시점에 RDD 연산으로 변환해 일반 스파크 잡으로 실행
- Json, Parquet 파일 포맷으로 사용됨
- 아파치 쓰리프트 서버 제공
- 아파치 쓰리프트 서버 - 외부 시스템과 스파크를 연동 외부시스템에서 기존 JDBC, OJDBC 프로토콜을 이용해 스파크 SQL 쿼리 실행 가능
2.3 스파크 스트리밍
- 실시간 데이터를 처리하는 프레임워크
- HDFS, KafKa, Apach Flume, ZeroMQ등
2.4 스파크 MLlib
- 머신러닝 알고리즘 라이브러리
2.5 스파크 GraphX
- 그래프 RDD형태의 그래프 구조를 만들어 그래프 알고리즘 제공
'BigData > Spark' 카테고리의 다른 글
| [Spark] RDD(Resilient Distributed Dataset) 개념과 연산 예제 (0) | 2021.11.06 |
|---|---|
| [개발] Spark SQL DataFrame Vector to Array (0) | 2021.10.21 |


댓글